Table of Contents
はじめに
今回は、DBのインデックスについてです。
SQLを使用して1万件以上のデータを持つDBにアクセスして検索結果を取得するとき、少しでも早く結果を取得できるならそうしたいですよね。そのためにDBの列に設定すべきなのがインデックスです。(※データ量で異なりますが、データが1万件未満だとインデックス設定はあまり効果がないかもしれません。)
例えば、英単語を調べるために辞書を見るとすると、どのページから見るでしょうか?まずは目次を見ますよね。
DBのインデックスはその目次のような感じです。目次を見てから目当てのページを探すと早く探せるように、インデックスによってDB内の該当するデータを探すのが早くなります。
カーディナリティ
列がもつ値のパターンの多さのことです。たとえば、「会員ID」だとカーディナリティが高く、「性別」はカーディナリティが低いと言います。
「会員ID」のようなカーディナリティが高い列に対してインデックスを設定するのが効果的とされています。
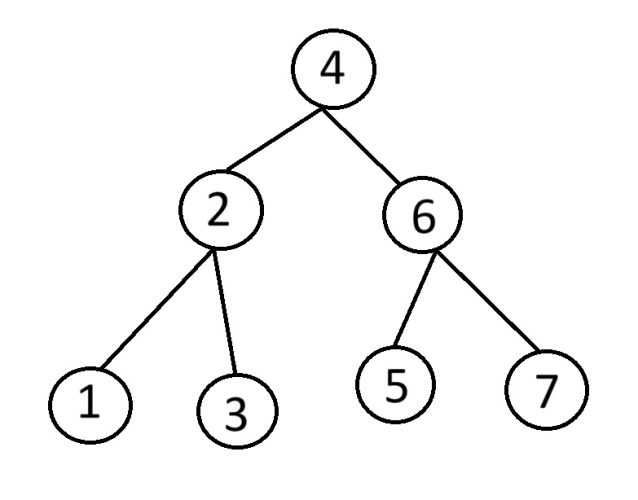
Bツリーインデックス
インデックスにはいくつか種類がありますが、代表的な「Bツリーインデックス」は、木の幹と枝のような構造となっているインデックスです。
親であるルート(=幹)ノードから、子である各ブランチ(=枝)ノードに辿っていくことで、効率的な探索ができるようになります。
インデックスの設定方法
インデックスを作成するには以下のSQL文を使用します。
CREATE INDEX [インデックス名] ON [テーブル名 (列名)];逆にインデックスを削除する場合は以下となります。
DROP INDEX [インデックス名] ON [テーブル名];インデックスの適用外
SQLによってはインデックスが適用されない場合があります。
以下は一例ですが、LIKE(あいまい)検索で、ワイルドカードが先頭にある場合はインデックスが有効となりません。
SELECT * FROM Aテーブル WHERE A列 LIKE '%test';逆に、ワイルドカードが後ろにある場合であれば、インデックスは有効となります。
SELECT * FROM Aテーブル WHERE A列 LIKE 'test%';最後に
インデックスを作成すると、デメリットが発生することもあります。テーブルへデータを追加する際など、すべてのインデックスにも追加されるため、速度が少し遅くなることがあります。
ただ、頻繁に膨大なデータ内を検索する際のメリットは大きいと思うので、必要性を見極めてインデックスを設定するようにしましょう。